I Am Not Going To Tag The Name Of The Bird, Because I’m Pretty Sure I Would Get Tagged As NSFW If I

I am not going to tag the name of the bird, because I’m pretty sure I would get tagged as NSFW if I did, but I assure you their beaks are getting longer and it’s probably because of the UK’s obsession with bird feeders.
More Posts from Science-is-magical and Others
A reminder that NASA isn’t the only space agency
I have seen many “Space achievements 2015” articles and posts leaving international accomplisments completely out, so here are some of them:
1. A new type of basaltic rock on the moon was found by Chinese robotic lander.
China National Space Administration’s Chang’e-3 landed on the Moon on 14 December 2013, becoming the first spacecraft to soft-land since the Soviet Union‘s Luna 24 in 1976.

2. On February 11, the European Space Agency, ESA, successfully launched on a suborbital trajectory and recovered an experimental wingless glider, IXV.
It became the first true “lifting body” vehicle, which reached a near-orbital speed and then returned back to Earth without any help from wings.

3. On December 9, Japan’s Akatsuki spacecraft succeeded entering orbit of Venus.
Japan Aerospace eXploration Agency’s Akatsuki is the first spacecraft to explore Venus since the ESA’s Venus Express reached the end of its mission in 2014.

4. ESA’s Rosetta spacecraft detected oxygen ‘leaking’ from comet 67P/Churyumov-Gerasimenko, the first time these molecules have been seen around a comet.
Rosetta spacecraft, the first to drop a lander (named Philae) on a comet, entered orbit around 67P in 2014 and continues to orbit the body. On June 13, European Space Operations Centre in Darmstadt, Germany, received signals from the Philae lander after months of silence.

5. The Canadian Space Agency has provided NASA with a laser mapping system that will scan an asteroid that could potentially hit the Earth in about 200 years

6. The high-resolution stereo camera on ESA’s Mars Express captured this sweeping view from the planet’s south polar ice cap and across its cratered highlands and beyond.

find Sci-Universe on Tumblr, Instagram & Facebook








(Image caption: In this illustration, a pair of eyeglasses “resolves” distinct serotonin neuron subtypes (shown as brightly colored cells) on a simple map of a region called the raphe in the mouse brain. By viewing serotonin neurons through multiple “lenses”—such as single-neuron and population-scale global gene expression, developmental lineage and anatomy—researchers have revealed diverse subtypes and principles of subtype organization in the brain. Credit: Mallory Rice)
Time for a New Definition
It used to be enough to call a serotonergic neuron a serotonergic neuron.
These brain cells make the neurotransmitter serotonin, which helps regulate mood, appetite, breathing rate, body temperature and more.
Recently, however, scientists have begun to learn that these neurons differ from one another—and that the differences likely matter in dysfunction and disease.
Last year, a team led by Harvard Medical School genetics professor Susan Dymecki defined a subgroup of serotonergic neurons in mice by showing that those cells specifically, among all serotonergic neurons, were responsible for increasing the breathing rate when too much carbon dioxide builds up in the body.
Now, Dymecki and colleagues have taken a first stab at systematically characterizing serotonergic neurons at the molecular level and defining a full set of subtypes, again in mice.
The researchers report in Neuron that serotonergic neurons come in at least six major molecular subtypes defined by distinct expression patterns of hundreds of genes. In many cases, the subtypes modulate different behaviors in the body.
By conducting a cross-disciplinary series of experiments, the researchers found that the subtypes also vary in their developmental lineage, anatomical distribution, combinations of receptors on the cell surface and electrical firing properties.
“This work reveals how diverse serotonin neurons are at the molecular level, which may help to explain how, collectively, they are able to perform so many distinct functions,” said Benjamin Okaty, a postdoctoral researcher in the Dymecki lab and co-first author of the paper.
“To have the list of molecular players that make each of these subtypes different from one another gives us an important handle on learning more about what that cell type does and how we can manipulate only that subtype,” said Dymecki. “It holds enormous therapeutic potential.”
“This is an ancient neurotransmitter system that’s implicated in many different diseases, and it’s starting to be cracked open,” said Morgan Freret, a graduate student in the Dymecki lab and co-first author of the paper. “We can now ask questions in a more systematic way about which serotonergic cells and molecules are important in, for example, pain, sleep apnea or anxiety.”
Crucially, the team also showed that a serotonergic neuron’s gene expression and function depend not only on its location in the adult brain stem, but also on its cellular ancestor in the developing brain.
“Earlier work had shown that you could explore the relationship between a mature neuronal system and the different developmental lineages that gave rise to it, but we had no idea whether it was meaningful,” said Dymecki. “We show that the molecular phenotypes of these neurons track quite tightly to their developmental origin, with anatomy making some interesting contributions as well.”
While the work was done in mice, Dymecki is optimistic that it will be replicated in humans because the serotonergic neuronal system is in a highly conserved region of the brain, meaning it tends to remain consistent across vertebrate species.
Because of this, researchers can look for the same molecular signatures in human tissue and begin to tease apart whether particular subtypes of serotonergic neurons are involved in conditions such as sudden infant death syndrome (SIDS) or autism.
Such research could ultimately reveal previously unknown contributions of the serotonergic neuronal system to disease, inform the development of biomarkers or lead to more targeted therapies.
The team’s findings could also inform stem cell research. “Which subtype of serotonergic neuron are we getting when we use current stem cell protocols?” asked Dymecki. “Can we drive the development of different subtypes? Can we watch how gene expression patterns change over time during development for each subtype?”
Finally, the study provides an example of a highly integrative approach to understanding brain function at multiple scales, “linking genes and gene networks to the properties of single neurons and populations of neuron subtypes, all the way up to the level of animal behaviors,” said Okaty. “I think it’s a useful template going forward. Imagine what we’d learn by applying this approach to all the neurotransmitter systems in the brain.”





Blind people gesture (and why that’s kind of a big deal)
People who are blind from birth will gesture when they speak. I always like pointing out this fact when I teach classes on gesture, because it gives us an an interesting perspective on how we learn and use gestures. Until now I’ve mostly cited a 1998 paper from Jana Iverson and Susan Goldin-Meadow that analysed the gestures and speech of young blind people. Not only do blind people gesture, but the frequency and types of gestures they use does not appear to differ greatly from how sighted people gesture. If people learn gesture without ever seeing a gesture (and, most likely, never being shown), then there must be something about learning a language that means you get gestures as a bonus.
Blind people will even gesture when talking to other blind people, and sighted people will gesture when speaking on the phone - so we know that people don’t only gesture when they speak to someone who can see their gestures.
Earlier this year a new paper came out that adds to this story. Şeyda Özçalışkan, Ché Lucero and Susan Goldin-Meadow looked at the gestures of blind speakers of Turkish and English, to see if the *way* they gestured was different to sighted speakers of those languages. Some of the sighted speakers were blindfolded and others left able to see their conversation partner.
Turkish and English were chosen, because it has already been established that speakers of those languages consistently gesture differently when talking about videos of items moving. English speakers will be more likely to show the manner (e.g. ‘rolling’ or bouncing’) and trajectory (e.g. ‘left to right’, ‘downwards’) together in one gesture, and Turkish speakers will show these features as two separate gestures. This reflects the fact that English ‘roll down’ is one verbal clause, while in Turkish the equivalent would be yuvarlanarak iniyor, which translates as two verbs ‘rolling descending’.
Since we know that blind people do gesture, Özçalışkan’s team wanted to figure out if they gestured like other speakers of their language. Did the blind Turkish speakers separate the manner and trajectory of their gestures like their verbs? Did English speakers combine them? Of course, the standard methodology of showing videos wouldn’t work with blind participants, so the researchers built three dimensional models of events for people to feel before they discussed them.
The results showed that blind Turkish speakers gesture like their sighted counterparts, and the same for English speakers. All Turkish speakers gestured significantly differently from all English speakers, regardless of sightedness. This means that these particular gestural patterns are something that’s deeply linked to the grammatical properties of a language, and not something that we learn from looking at other speakers.
References
Jana M. Iverson & Susan Goldin-Meadow. 1998. Why people gesture when they speak. Nature, 396(6708), 228-228.
Şeyda Özçalışkan, Ché Lucero and Susan Goldin-Meadow. 2016. Is Seeing Gesture Necessary to Gesture Like a Native Speaker? Psychological Science 27(5) 737–747.
Asli Ozyurek & Sotaro Kita. 1999. Expressing manner and path in English and Turkish: Differences in speech, gesture, and conceptualization. In Twenty-first Annual Conference of the Cognitive Science Society (pp. 507-512). Erlbaum.

From retina to cortex: An unexpected division of labor
Neurons in our brain do a remarkable job of translating sensory information into reliable representations of our world that are critical to effectively guide our behavior. The parts of the brain that are responsible for vision have long been center stage for scientists’ efforts to understand the rules that neural circuits use to encode sensory information. Years of research have led to a fairly detailed picture of the initial steps of this visual process, carried out in the retina, and how information from this stage is transmitted to the visual part of the cerebral cortex, a thin sheet of neurons that forms the outer surface of the brain. We have also learned much about the way that neurons represent visual information in visual cortex, as well as how different this representation is from the information initially supplied by the retina. Scientists are now working to understand the set of rules—the neural blueprint— that explains how these representations of visual information in the visual cortex are constructed from the information provided by the retina. Using the latest functional imaging techniques, scientists at MPFI have recently discovered a surprisingly simple rule that explains how neural circuits combine information supplied by different types of cells in the retina to build a coherent, information-rich representation of our visual world.
Vision begins with the spatial pattern of light and dark that falls on the retinal surface. One important function performed by the neural circuits in the visual cortex is the preservation of the orderly spatial relationships of light versus dark that exist on the retinal surface. These neural circuits form an orderly map of visual space where each point on the surface of the cortex contains a column of neurons that each respond to a small region of visual space— and adjacent columns respond to adjacent regions of visual space. But these cortical circuits do more than build a map of visual space: individual neurons within these columns each respond selectively to the specific orientation of edges in their region of visual space; some neurons respond preferentially to vertical edges, some to horizontal edges, and others to angles in between. This property is also mapped in a columnar fashion where all neurons in a radial column have the same orientation preference, and adjacent columns prefer slightly different orientations.
Things would be easy if all the cortex had to do was build a map of visual space: a simple one to one mapping of points on the retinal surface to columns in the cortex would be all that was necessary. But building a map of orientation that coexists with the map of visual space is a much greater challenge. This is because the neurons of the retina do not distinguish orientation in the first step of vision. Instead, information on the orientation of edges must be constructed by neural circuits in the visual cortex. This is done using information supplied from two distinct types of retinal cells: those that respond to increases in light (ON-cells) and those that respond to decreases in light (OFF-cells). Adding to the complexity, orientation selectivity depends on having individual cortical neurons receive their ON and OFF signals from non-overlapping regions of visual space, and the spatial arrangement of these regions determines the orientation preference of the cell. Cortical neurons that prefer vertical edge orientations have ON and OFF responsive regions that are displaced horizontally in visual space, those that prefer horizontal edge orientations have their ON and OFF regions displaced vertically in visual space, and this systematic relationship holds for all other edge orientations.
So cortical circuits face a paradox: How do they take the spatial information from the retina and distort it to create an orderly map of orientation selectivity, while at the same time preserving fine retinal spatial information in order to generate an orderly map of visual space? Nature’s solution might best be called ‘divide and conquer’. By using imaging technologies that allow visualization of the ON and OFF response regions of hundreds of individual cortical neurons, Kuo-Sheng Lee and Sharon Huang in David Fitzpatrick’s lab at MPFI have discovered that fine scale retinal spatial information is preserved by the OFF response regions of cortical neurons, while the ON response regions exhibit systematic spatial displacements that are necessary to build an orderly map of edge orientation. Preserving the detailed spatial information from the retina in the OFF response regions is consistent with evidence that dark elements of natural scenes convey more fine scale information than the light elements, and that OFF retinal neurons have properties that allow them to better extract this information. In addition, Lee et al. show that this OFF-anchored cortical architecture enables emergence of an additional orderly map of absolute spatial phase—a property that hasn’t received much attention from neuroscientists, but computer vision research has shown contains a wealth of information about the visual scene that can be used to efficiently encode spatial patterns, motion, and depth.
While these are important new insights into how visual information is transformed from retina to cortical representations, they pose a host of new questions about the network of synaptic connections that performs this transformation, and the developmental mechanisms that construct it, questions that the Fitzpatrick Lab continues to explore.


Timelapse of Europa & Io orbiting Jupiter, shot from Cassini during its flyby of Jupiter


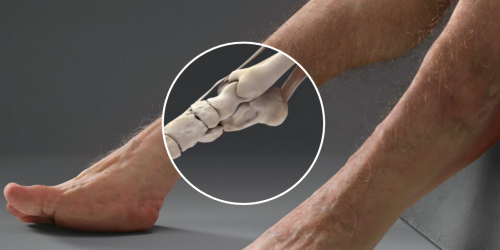
Here’s how nightmarish humans would look if our bodies were designed to survive car crashes
Article by Chris Weller, Tech Insider & Business Insider
If you’re ever in a car with Graham, then don’t bother telling him to buckle his seat belt. His body is already designed to withstand high-speed impacts.
Designed by a trauma surgeon, an artist, and a crash investigator, Graham is a hypothetical scenario come to life. Supported by Australia’s Transport Accident Commission, the project is meant to highlight how vulnerable humans are to injury.
Graham, however, is not.
Keep reading
-
 shadowkat2000 liked this · 1 week ago
shadowkat2000 liked this · 1 week ago -
 conlainn reblogged this · 1 week ago
conlainn reblogged this · 1 week ago -
 trans-cyberian-orchestra liked this · 1 month ago
trans-cyberian-orchestra liked this · 1 month ago -
 rikkirattus reblogged this · 1 month ago
rikkirattus reblogged this · 1 month ago -
 cuquas reblogged this · 1 month ago
cuquas reblogged this · 1 month ago -
 ahni-animalia reblogged this · 1 month ago
ahni-animalia reblogged this · 1 month ago -
 imajica1863 reblogged this · 2 months ago
imajica1863 reblogged this · 2 months ago -
 wcdonaldo liked this · 2 months ago
wcdonaldo liked this · 2 months ago -
 nebuluna78 reblogged this · 2 months ago
nebuluna78 reblogged this · 2 months ago -
nebuluna78 liked this · 2 months ago
-
 evergreenalice reblogged this · 2 months ago
evergreenalice reblogged this · 2 months ago -
 nyarlathesleeper reblogged this · 2 months ago
nyarlathesleeper reblogged this · 2 months ago -
nyarlathesleeper liked this · 2 months ago
-
 kaikinapela reblogged this · 2 months ago
kaikinapela reblogged this · 2 months ago -
 cerealnuee reblogged this · 2 months ago
cerealnuee reblogged this · 2 months ago -
cerealnuee liked this · 2 months ago
-
 dimobserver reblogged this · 4 months ago
dimobserver reblogged this · 4 months ago -
dimobserver liked this · 4 months ago
-
 fishboy44 liked this · 4 months ago
fishboy44 liked this · 4 months ago -
 dorminchu liked this · 4 months ago
dorminchu liked this · 4 months ago -
 kettyjay reblogged this · 4 months ago
kettyjay reblogged this · 4 months ago -
kettyjay liked this · 4 months ago
-
 pirateplates reblogged this · 4 months ago
pirateplates reblogged this · 4 months ago -
 pyriteplates liked this · 4 months ago
pyriteplates liked this · 4 months ago -
 gemwolfz reblogged this · 4 months ago
gemwolfz reblogged this · 4 months ago -
 ellias-elliott liked this · 4 months ago
ellias-elliott liked this · 4 months ago -
 exiledfrommars liked this · 4 months ago
exiledfrommars liked this · 4 months ago -
 bloodpraxis liked this · 4 months ago
bloodpraxis liked this · 4 months ago -
 autisticdrizzt reblogged this · 4 months ago
autisticdrizzt reblogged this · 4 months ago -
 foxboyclit liked this · 4 months ago
foxboyclit liked this · 4 months ago -
 cacturne reblogged this · 4 months ago
cacturne reblogged this · 4 months ago -
cacturne liked this · 4 months ago
-
 laissez-faerie reblogged this · 4 months ago
laissez-faerie reblogged this · 4 months ago -
 flying-butter reblogged this · 5 months ago
flying-butter reblogged this · 5 months ago -
 tabbycatsdream reblogged this · 5 months ago
tabbycatsdream reblogged this · 5 months ago -
tabbycatsdream liked this · 5 months ago
-
 wolfsrahne28 liked this · 6 months ago
wolfsrahne28 liked this · 6 months ago -
 chancellorgriffin-blog reblogged this · 7 months ago
chancellorgriffin-blog reblogged this · 7 months ago -
 nanni-shall-be-restored-in-full reblogged this · 7 months ago
nanni-shall-be-restored-in-full reblogged this · 7 months ago -
 eonityluna reblogged this · 7 months ago
eonityluna reblogged this · 7 months ago -
eonityluna liked this · 7 months ago
-
 facepalmmylifeu liked this · 8 months ago
facepalmmylifeu liked this · 8 months ago -
 surfs-updude liked this · 10 months ago
surfs-updude liked this · 10 months ago -
 transpotato5 liked this · 11 months ago
transpotato5 liked this · 11 months ago -
 what-are-fish reblogged this · 11 months ago
what-are-fish reblogged this · 11 months ago -
 scarredstars-blog liked this · 11 months ago
scarredstars-blog liked this · 11 months ago -
 bloggingfromthedeltaquadrant reblogged this · 11 months ago
bloggingfromthedeltaquadrant reblogged this · 11 months ago
